什么是聚类分析
更多操作可查看《如何使用聚类分析》、《如何解读分析结果》。
什么是聚类分析?
聚类分析是数据挖掘领域最重要的研究分支之一,是一种基于事物自身的特征将其进行分组的统计分析方法。
将聚类分析应用在人群分组中时,它将能够帮助您从海量的用户数据中,分析出具有相似行为特征的用户群体,在用户生命周期分析和精准营销领域有着广泛的使用价值。
聚类分析界面介绍
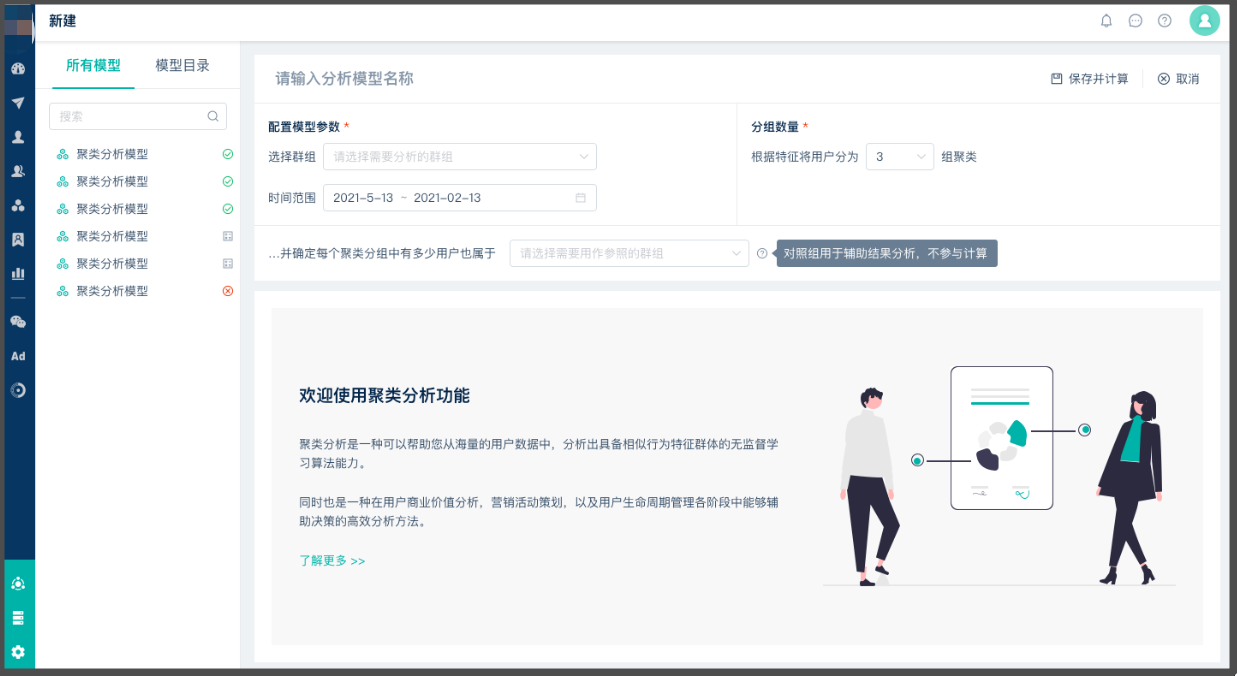
「页面左侧区域」为已创建的分析模型列表,您可以在此管理并查看已经计算完成,和仍然处于计算队列中的分析模型;
「页面右侧区域」为参数配置区域,您可以在此区域中配置您的模型参数,之后系统将基于参数生成离线的聚类分析任务,并在计算完成后将结果展示在当前区域;
配置参数说明
{ 选择群组 } 参数:选择全部用户或某个已经创建的群组,系统将对该群组内的用户进行聚类分组分析;
{ 时间范围 } 参数:选择一个过去的时间范围,系统将会基于在该时间范围内用户进行的交互事件数据对所选群组进行聚类分析;
{ 分组数量 } 参数:选择一个 2~30 之间的分组数,系统将会基于该分组数设定最终生成的聚类分组的数量;
{ 对照组 } 参数:选择一个用作人群对照的群组,该群组不参与分析算法的计算,您可以通过对照组和不同聚类分组间的用户重叠度来进一步分析生成群组的价值;
聚类分析的优势
与基于阈值/规则的人群细分相比,聚类分析具备一下三个主要优势:
1、无需先验规则,能够通过分析数据自行揭示分组依据;
2、大数据架构能够从更多维度上精准细分客户,这在传统的阈值/规则上基本不可实现;
3、更科学的分组粒度,组内用户的差异更小,行为相似度更高;
聚类分析的原理?
聚类分析概述
聚类分析(英语:Cluster analysis)亦称为集群分析,是对于统计数据分析的一门技术,在许多领域受到广泛应用,包括机器学习,数据挖掘,模式识别,图像分析以及生物信息。聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。[引用1]
聚类分析特征
聚类分析是根据事物本身的特性研究个体的一种方法,目的在于将相似的事物归类。它的原则是同一类中的个体有较大的相似性,不同类的个体差异性很大。这种方法有三个特征[引用2]:
1、适用于没有先验知识的分类。如果没有这些事先的经验或一些国际标准、国内标准、行业标准,分类便会显得随意和主观,这时只要设定比较完善的分类变量,就可以通过聚类分析法得到较为科学合理的类别;
2、可以处理多个变量决定的分类。例如,要根据消费者购买量的大小进行分类比较容易,但如果在进行数据挖掘时,要求根据消费者的购买量、家庭收入、家庭支出、年龄等多个指标进行分类通常比较复杂,而聚类分析法可以解决这类问题:
3、聚类分析法是一种探索性分析方法,能够分析事物的内在特点和规律,并根据相似性原则对事物进行分组,是数据挖掘中常用的一种技术。
基于K-Means的聚类分析
聚类分析领域涵盖多种计算方式和相关算法,其中在商业中比较通用的是K-Means算法,下文介绍以K-Means算法为例。
使用K-Means算法进行聚类分析的过程可以简单划分为7个阶段:
1、决定聚类分组数K
2、在欧式空间中随机定义K个初始中心坐标点
3、计算空间中每个数据点距离每个初始中心坐标点的距离,对数据点进行分组
4、计算每个分组内数据点的均值,从而得到新的中心坐标点
5、【迭代】计算空间中每个数据点距离新的中心坐标点的距离,对数据点进行重新分组
6、【迭代】计算每个分组内数据点的均值,从而得到新的中心坐标点
7、反复执行迭代过程,直到每个分组的新的中心坐标点位置不再变更
相关资料
引用1:维基百科,点击查看
引用2:MBA智库百科,点击查看
引用3:百度百科,点击查看
引用4:维基百科,点击查看
引用5:github/Matplotlib_animation,点击查看
引用6:github/kmeans,点击查看
引用7:欧式距离,点击查看
(以2维数据集为例,上方图片来自于[引用6])