生命周期价值预测
什么是预测客户生命周期价值?
客户生命周期价值是指基于客户与公司的整个关系期间归属于客户的未来现金流量的现值。通俗来说,它是指客户在一段周期内在企业产品上进行消费的消费总金额。
通过机器学习算法用户在系统内的历史消费数据、历史行为数据和用户属性等多维度的数据进行建模分析,利用数据的内禀属性和关联关系,能够预测单个活跃用户在未来时间段内为您的公司带来的潜在生命周期价值。根据预测结果您可以更具倾向性的进行营销活动,从而最大限度的提高转化率。该功能为您能够带来:
识别高价值客户——通过机器学习算法能够识别出系统内的高价值客户
更具倾向性的营销活动——预测的结果能够使得您的营销活动时瞄准正确的客户从而实现营销目标
减少营销成本增加收入——能够帮助您很快的定位营销目标,降低了泛投的风险
自由的营销活动配置——能够在群组/标签/客户旅程中便捷的使用预测结果标签
更完善的客户资料——通过数据洞察形成更加完善的用户画像资料
基于业务的定制化配置——客户只需要少量的配置即可创建符合自身业务场景的预测模型
更直观的模型可视化——多种指标的展示面板辅助客户理解模型
我们是如何进行预测的?
用户在消费前往往存在一系列决策过程,传统的用户消费过程通常分为四个阶段 [ 来源:维基百科 & 百度百科 ] 。

每个决策阶段内的用户都将产生一系列的活跃行为事件,而具备相似行为事件的用户其决策阶段和付费行为也趋近于相似。当您开启预测客户生命周期价值时,系统首先将基于您系统内的历史订单数据,根据其在近期是否产生过购买行为,将用户区分成两组(付费组和未付费组)。之后系统将分别确认这两组内的用户在进入系统中直到分析开始时分别执行过哪些行为事件,没有执行哪些行为事件。
接下来,系统将会基于三组变量比较和分析两组数据:用户属性,用户事件,用户订单
用户属性:包括用户预置属性和自定义属性
用户事件:包括用户预置事件和相关事件的统计数
用户订单:包括用户订单事件,及相关事件的统计数
最终,系统将全部数据集合到逻辑回归模型中,创建一个具备数百个参数的分析模型,分别预测用户的潜在交易概率、潜在交易次数和单次交易金额。根据参数可计算:

计算完成后模型将为每个参与分析的用户生成客户生命周期价值的预测值,并作为用户标签关联在用户上。
// 通用模型的预测金额并未乘以贴现率(Discount Rate),如果需要考虑贴现率需要单独进行处理。
模型输入数据
| 数据类型 | 描述 | 示例数据 |
|---|---|---|
| 用户属性 | 包含系统预置的属性和用户自定义的属性,用户性别,国家,喜爱的品牌等 | 居住的城市,星座等 |
| 事件 | 包含系统预置事件,记录用户历史互动行为数据 | 网站访问事件,评论事件 |
| 订单 | 用户订单数据,记录用户的历史交易行为数据 | 交易事件,支付事件 |
如何使用该功能?
使用路径:【用户标签】>开通后会显示三个标签,分别是:《客户生命周期价值_90天》、《客户生命周期价值_180天》、《客户生命周期价值_365天》
1、系统内至少具备1年以上的订单交易事件(2年以上为佳),每月至少有10名活跃客户,总客户数不少于200名。订单数据应该至少具备订单状态、订单金额、订单时间、用户ID和订单ID等关键字段,关键字段缺失率不超过20%。
2、如果要开启该功能,需要通过运营经理申请后台开启。
3、由于预测结果是基于历史数据的建模分析,因此结果可能存在误差。我们建议您将预测结果作为参考,而不是绝对的决策依据。
4、预测结果会受到多种因素的影响,比如用户行为变化、市场环境变化等。因此,我们建议您定期更新并查看预测结果,以保持其准确性。
5、如果您在使用过程中遇到任何问题或者有任何建议,请随时联系我们的客服团队,我们将竭诚为您服务。
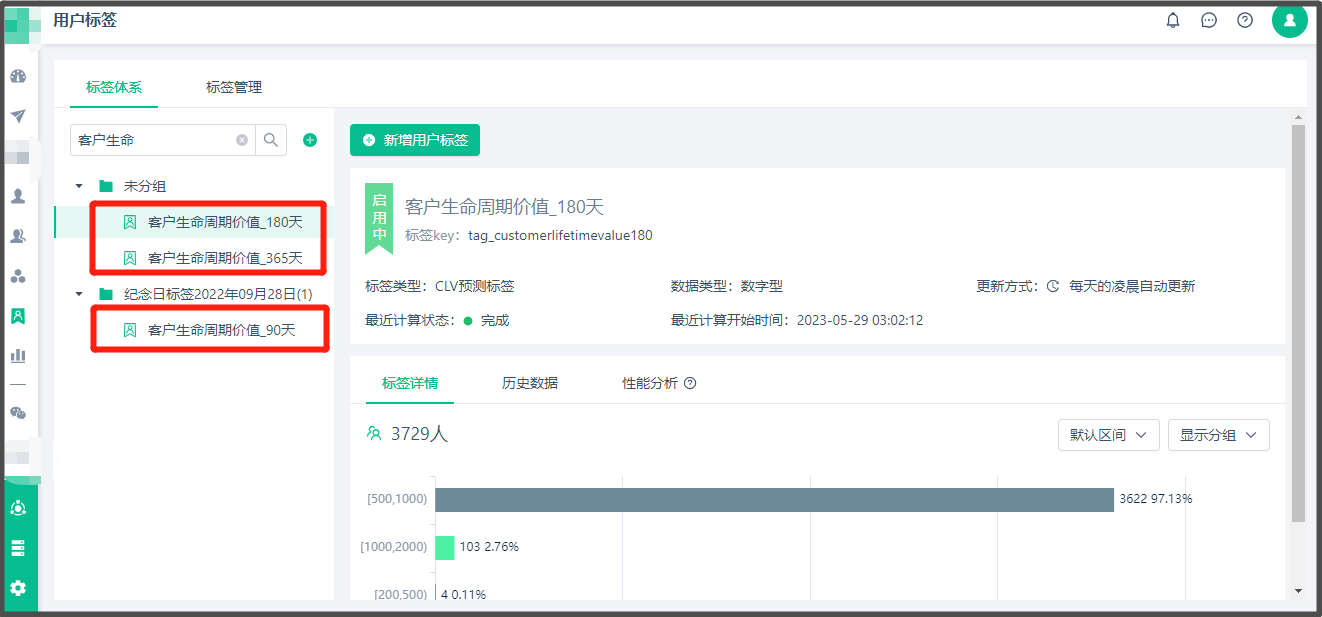
页面一、【标签详情】
生命周期价值预测任务与系统内通用的数字型标签任务展示方式一致,您可以在标签详情页面查看到预测值的分布结果。
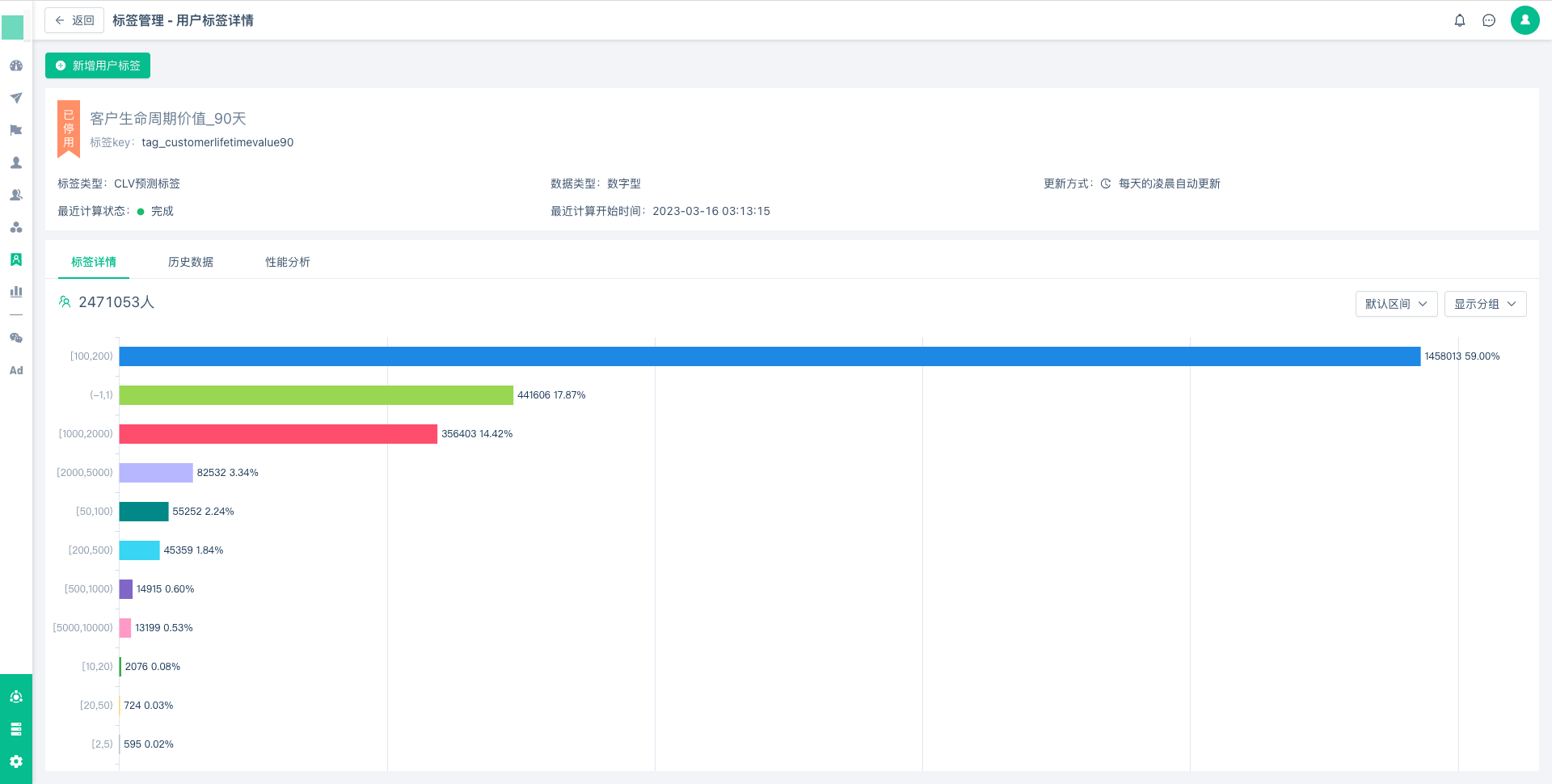
页面二、【历史数据】
您也可以在历史数据一栏中,查看标签数据跟随日期的分布状况。
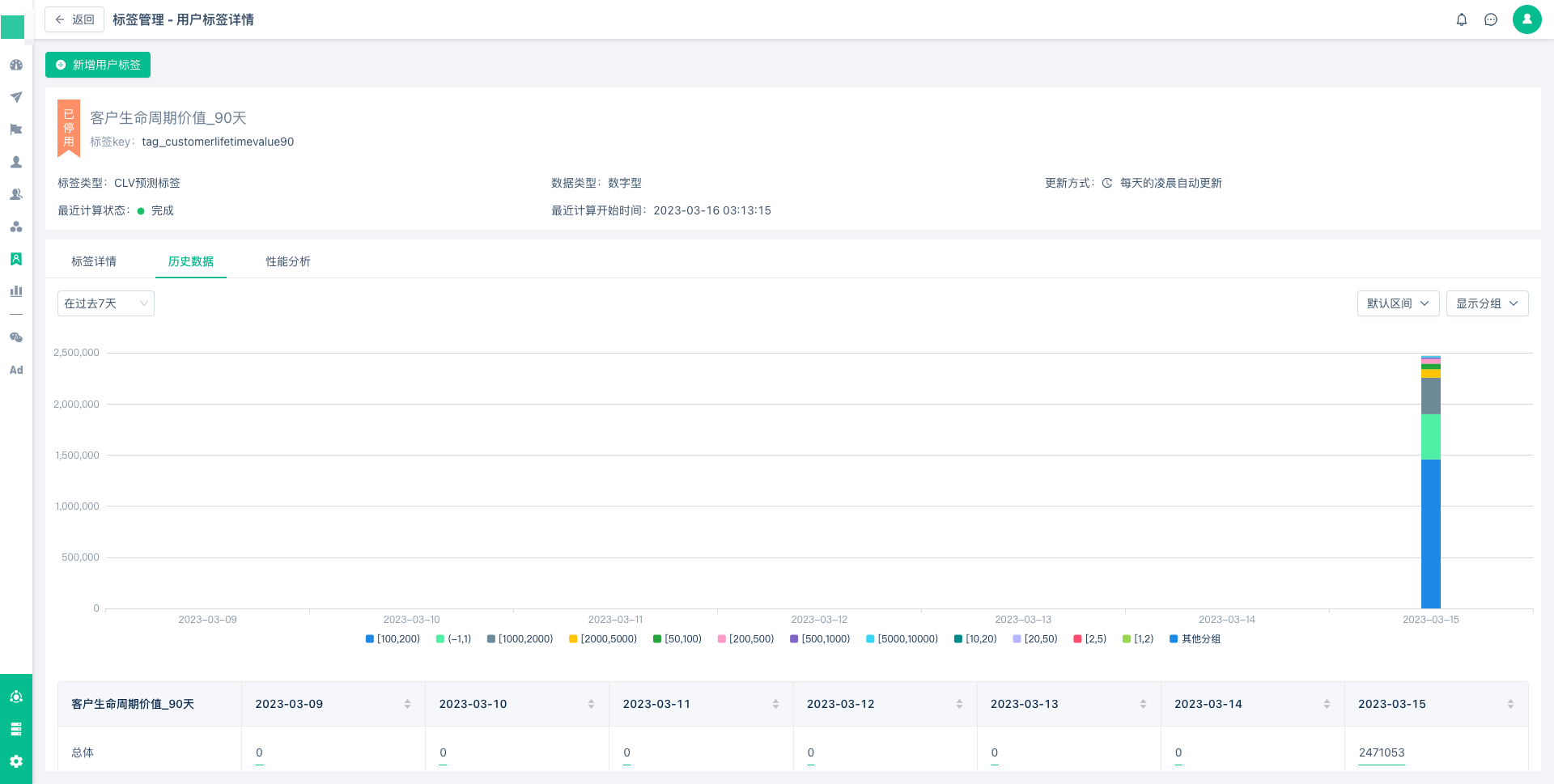
页面三、【性能分析】
最后您可以在性能分析一栏中,查看有关模型训练状态和训练特征的展示列表。
您可以在上侧查看到模型的更新信息(我们会基于您最新的数据定期更新模型,通常为每周一次)。
最近模型训练:展示您最近训练模型的日期
训练状态:成功/失败/停止,您可以在该字段查看到模型训练状态。
当前模型于XXXX-XX-XX生成:展示目前计算使用模型的生成时间,如果某个周期内数据量过少,则该周期内的模型可能存在更新失败的状况,此时在进行任务时将自动使用上一次成功的模型进行预测。
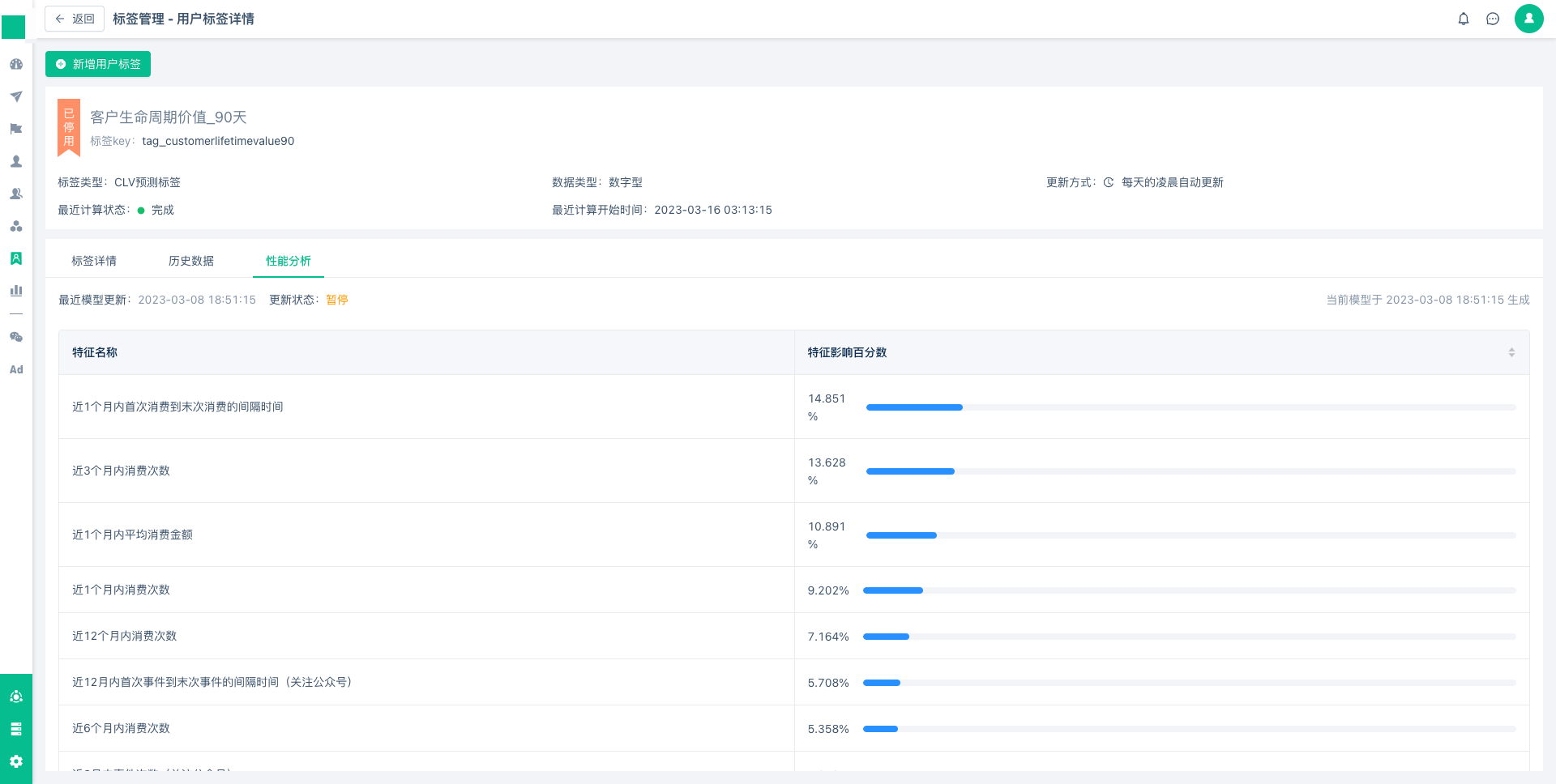
页面下方展示的是进行建模分析时对预测结果产生了决定性影响的特征及对应的特征贡献度,其贡献度在一定程度上表示该特征在数据集时的显著性,百分数数值的高和低不代表属性的数量,例如系统内共10001名用户,所有用户均具备性别属性,其中10000名用户的性别为“女”,只有1名用户性别为“男”,这时性别属性这个特征的方差无限接近于零,该特征不发散则在进行分析时则通常不具备显著性,无法作为逻辑回归的参考依据。
特征影响百分数(特征贡献度):您可以通过该数值了解哪些因素对客户生命周期价值的预测结果产生决定性影响,或者说哪些因素在用户进行决策过程中导致了用户走向不同分支,从而可以倾向性的对用户进行引导营销。
例如:如果您发现关注公众号事件对于预测结果的贡献度百分数较高,则说明用户在面临消费抉择时是否关注公众号成为了一个影响点,您还可以以此进行进一步的数据洞察和判断,到底是关注了公众号的用户CLV更高,还是未关注公众号的用户CLV更高?造成这方面差异的影响是什么?是公众号推文频繁导致复购?还是推文太多导致用户流失?这将成为辅助您营销的关键助力点。
关于特征工程
在进行建模分析之前,我们会对系统内的元事件数据进行特征工程处理。这个处理过程包括降维、剪枝、去重和删除等多个步骤,旨在使得输出的特征更加易于建模和分析。为了能够更加方便的解读其含义,处理后的特征命名通常按照一定的规律生成。我们目前生成的特征主要分为三类:订单统计特征,事件统计特征和用户属性。这些特征的明确含义请见下方,【左侧:特征名称;右侧:解释说明】
类别一、订单统计特征(基于RFM):
近X个月内实际消费金额:指X月内完成状态订单的消费总金额。
近X个月内消费次数:指X月内完成状态订单的消费总次数。
近X个月内平均消费金额:指X月内完成状态订单的平均消费金额。
近X个月内首次消费到末次消费的间隔时间:指X月内,首末两次订单完成事件间的间隔时间,例如X月内第一次订单的时间为3月1日,最后一次订单的时间为4月1日,则间隔时间为1个月。
近X个月内首次消费到特征期结束的间隔时间:指X月内,首次订单完成事件到模型开始训练的间隔时间,例如例如X月内第一次订单的时间为3月1日,分析模型在5月1日开始采样计算,则间隔时间为2个月。
近X个月内消费的平均间隔时间:指X月内完成状态订单时间的平均间隔时间。
用户首次消费时间:指X月内用户首次产生完成状态订单事件的时间。
用户最近一次消费时间:指X月内最后一次产生完成状态订单事件的时间。
类别二、事件统计特征:
近X月内事件次数(XX):与订单特征类似,即发生括号内事件的事件统计次数。例如近X月内发生关注公众号事件的事件次数。
近X月内首次事件到末次事件的间隔时间(XXX):略
近X月内首次事件到特征期结束的间隔时间(XXX):略
近X月内事件的平均间隔时间(XXX):略
用户最近一次事件时间(XXX):略
类别三、用户属性:
属性名称XXX_属性值XXX:部分用户属性以属性和属性值作为分析特征,例如性别_male、性别_famale、性别_unknown,下划线后即为性别属性的属性值。
属性名称XXX:部分用户属性以有无该属性作为分析特征,例如手机号、邮箱、城市等,则只有属性名称,不展示其属性值。
如何开通CLV功能
此功能为付费功能,如需开动此功能,烦请联系我司商务!