用户自定义预测
什么是自定义预测标签功能?
自定义预测标签是Linkflow基于机器学习能力研发的高级功能。相较于传统的营销方式,如今的消费者对于在与各个品牌互动时的个性化体验要求更高。而作为营销人员,往往就面临着要准确预测客户兴趣与意向,并制定最佳行动决策的挑战。通过自定义预测标签功能,您可以创建定制化的训练模型,并利用机器学习模型计算每个客户执行业务目标或处于某状态的可能性,从而在进行营销活动时精准的选择目标受众,从而最大限度的提高营销转化率。该功能为您能够带来:
更精准的识别目标用户——您可以基于营销目标和业务场景为您的活动创建更贴合的人群细分
更具倾向性的营销活动——预测的结果能够使得您的营销活动时瞄准正确的客户从而实现营销目标
减少营销成本增加收入——能够帮助您很快的定位营销目标,降低了泛投的风险
自由的营销活动配置——能够在群组/标签/客户旅程中便捷的使用预测结果标签
更完善的客户资料——通过数据洞察形成更加完善的用户画像资料
基于业务的定制化配置——只需要进行简单的配置就可以创建基于自有数据的个性化预测模型
自动化的模型构建——从特征工程的数据规范化到模型fine-tune的调优过程全部自动化
更直观的模型可视化——多种指标的展示面板辅助客户理解模型
自定义预测的使用场景示例
自定义预测标签的定制化配置能力使得其具备广泛的使用场景,针对不同的业务需求,您可以预测用户付费、流失、订阅、收藏、页面停留等概率,以下为部分使用场景示例:
| 预测类型 | 场景说明 |
|---|---|
| 转化 | 线上购物、旅游网站、金融服务等网站中,通常有一系列提交表单/预订/审核等步骤,通过该功能可以预测用户在转化漏斗中到达某阶段的可能性,从而进行针对性的帮助和营销。 |
| 活跃 | 线上网站/应用程序平台中,DAU/MAU都是相对重要的分析指标,通过该功能可以预测用户在一段窗口期内回到网站/应用程序的可能性,从而对客户群进行针对性的唤醒及促活。 |
| 流失 | 客户流失也是品牌营销中重要的分析指标,通过对用户流失概率的预测,可以分析流失率的变化倾向,从而在营销关键节点内进行客户挽回。 |
| 付费 | 通过该功能您可以预测用户进行购买/订阅等行为的可能性,从而在优惠劵策略,通知策略上进行特定处理从而提高品牌销售额。 |
模型输入数据
| 数据类型 | 描述 | 示例数据 |
|---|---|---|
| 用户属性 | 包含系统预置的属性和用户自定义的属性,用户性别,国家,喜爱的品牌等 | 居住的城市,星座等 |
| 事件 | 包含系统预置事件,记录用户历史互动行为数据 | 网站访问事件,评论事件 |
| 订单 | 用户订单数据,记录用户的历史交易行为数据 | 交易事件,支付事件 |
如何创建自定义预测标签?
1、系统内至少具备1年以上的订单交易事件(2年以上为佳),每月至少有10名活跃客户,总客户数不少于200名。订单数据应该至少具备订单状态、订单金额、订单时间、用户ID和订单ID等关键字段,关键字段缺失率不超过20%。
2、模型创建时的初次训练预计需要20小时,后续模型每7天将基于最新数据重新进行训练。
3、如果要开启该功能,需要通过CSM申请后台开启。
4、由于预测结果是基于历史数据的建模分析,因此结果可能存在误差。我们建议您将预测结果作为参考,而不是绝对的决策依据。
5、预测结果会受到多种因素的影响,比如用户行为变化、市场环境变化等。因此,我们建议您定期更新并查看预测结果,以保持其准确性。
6、如果您在使用过程中遇到任何问题或者有任何建议,请随时联系我们的客服团队,我们将竭诚为您服务。
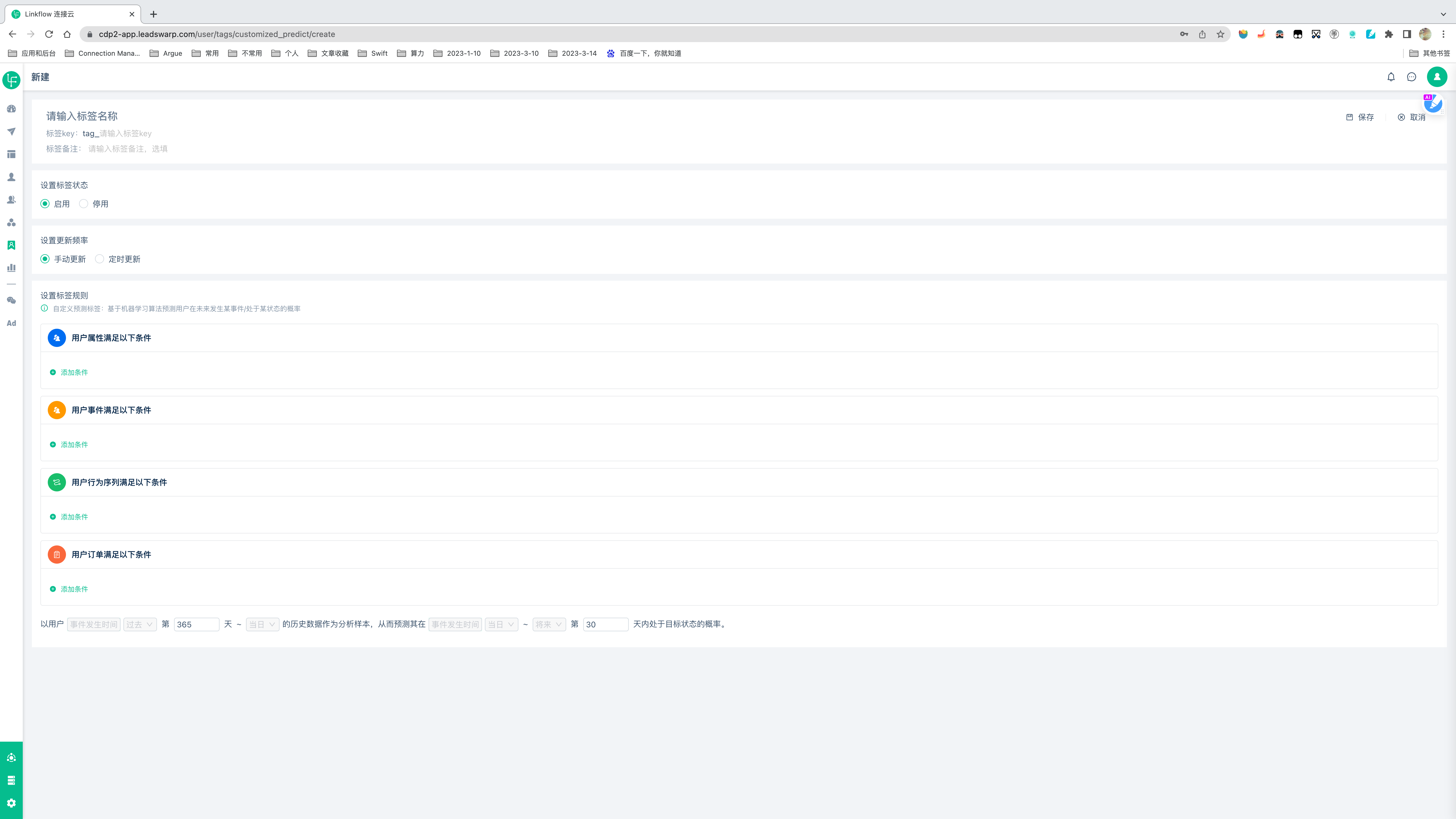
创建自定义标签,需要用户前往「用户标签」→「标签管理」页面,在「新建用户标签」的弹窗列表中选择「自定义预测标签」。
配置一个自定义标签需要三步:
1、设置标签状态&更新频率;(其中更新频率是指标签的计算频率,而非模型训练的频率)
2、定义需要预测目标的筛选条件;(例如:如果希望预测用户访问公众号的概率,则在“用户事件满足以下条件”处选择「访问公众号」事件,并配置对应的事件属性即可)
3、定义预测的事件窗口期;(模型的历史数据窗口期以及模型的预测窗口期)
关于预测目标筛选条件
您可以将希望预测的事件/状态配置为判断条件,例如如果您希望预测用户付费事件,您可以在订单条件中设置为订单数量≧1,如果对预测事件的订单金额有要求,则可以设置订单金额≧1000元。配置完成后,模型在预测时计算的结果就是用户未来产生消费并订单金额大于等于1000元这个事件的发生概率。但同时请了解,配置预测目标条件时需要基于实际业务需求场景进行操作,如果随意配置Outbound事件,预测结果将可能不具备实际意义;例如如果目标条件为,预测未来7天LF给客户发送短信的概率,由于短信发送事件是LF主动发起的,所以如果您已经关闭了LF的短信发送功能,那么无论预测的结果为多少,实际发生的概率都几乎为零,这样的预测便不具备实际使用价值。
关于预测窗口期
预测窗口期的配置取决于您的实际需求,通常该周期与您业务转化漏斗的窗口期息息相关。并且您记录历史数据的时间范围不应该小于该窗口期,例如如果用户配置历史数据窗口期为60天,预测窗口期30天,则系统内至少需要拥有历史90天的数据(历史数据窗口期+预测窗口期)来进行模型创建。

补充说明:当您创建模型后,系统将基于历史30-90范围的数据对预测历史30天内发生的实际事件进行建模,从而了解哪些行为模型会导致预测目标的发生。进而预测未来30天发生预测目标的可能性。
模型结果的可视化和说明
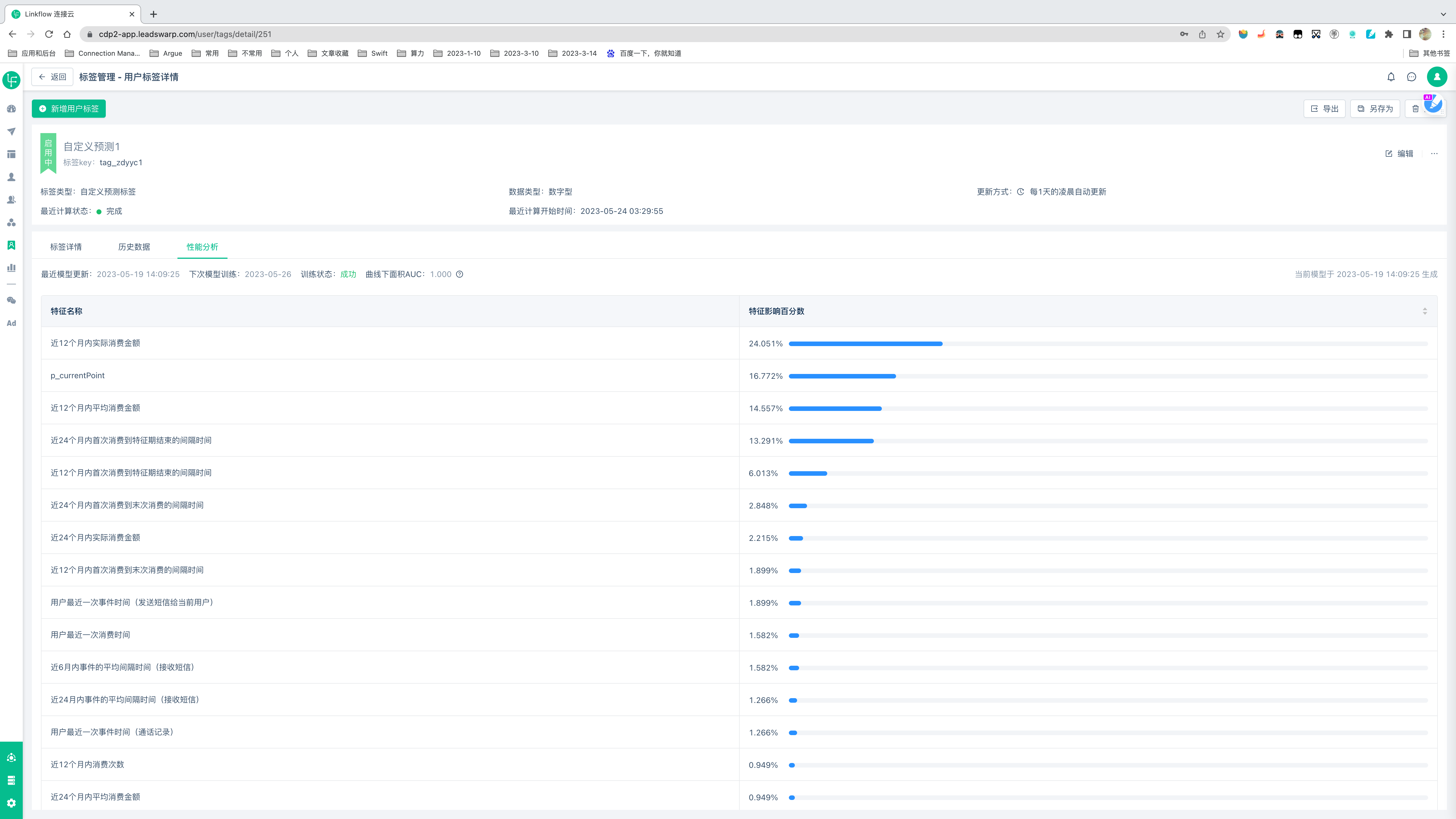
模型计算完成后将为每个客户生成一个0到1之间的概率预测值作为用户标签值,较高的概率表示客户实现预期目标的可能性较高。除此之外您还可以在「模型信息」页面查看到模型的三部分信息:
1、模型状态信息
最近模型训练:即模型最近一次完成训练的时间,从模型创建之日起,每7天模型将基于最新的数据重新完成一次训练。
下次模型训练:即模型下一次的训练时间,预计到达该时间点时模型将会开启下次训练。如果您在训练日时停用模型,模型将跳过此次训练。
训练状态:模型最近一次训练的训练状态,总共有三种状态,成功/失败/停止,通常数据过少或数据异常时会导致训练失败。
当前模型生成时间:从模型创建之日起,每次使用最新数据训练时都会对模型进行评分,系统会自动采用性能最好的模型执行预测任务,因此随着模型训练次数的增多,模型预测的准确率也将逐渐增高。
2、模型评价指标
曲线下面积AUC:AUC通常被用来作为衡量分类结果准确的指标,AUC的数值范围为0-1,AUC = 1,说明模型是完美分类器,预测结果完美准确;AUC = [0.85, 0.95],说明分类效果很好;AUC = [0.7, 0.85],说明分类效果一般;AUC = [0.5, 0.7],说明分类效果较低;AUC = 0.5,分类预测概率跟随机猜测一样(例:丢铜板),模型没有预测价值;AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。[百度百科]
3、模型特征重要性指标
模型特征重要性图表:以图表的方式展示模型训练中具有意义的特征,通过该图表可以帮助您了解到哪些事件在模型构建中起到了主要贡献。
自定义预测标签的原理
自定义预测的常见使用
自定义预测结果会作为标签值展示在「用户详情」页面的标签展示框上。
1、您可以以此作为分组依据创建用户细分;
2、您可以在客户旅程中使用自定义预测的标签值作为分支条件,对不同的细分人群进行个性化营销;
3、您可以将预测结果与报表分析相结合进行多维度的客户分析;
4、您可以将自定义预测的值导出到第三方工具中从而在在第三方工具中进行精细化营销;
5、您可以将标签值与A/B测试功能结合在营销推广前进行效果验证;
提示语说明
| 提示语 | 解释 |
|---|---|
| 模型训练预计需要20小时,请稍后再试。 | 当您进行手动计算操作时,可能会弹出该提示语,通常是由于系统正在进行建模前的准备工作,包括数据采集,数据归一和特征处理,基于您配置的预测目标的复杂度,该流程通常需要耗费2~20小时不等,请您耐心等待。 |
| 无满足条件的正样本,无法计算。 | 当您进行手动计算操作时,可能会弹出该提示语,通常是由于系统内预测目标的用户数不足导致的,机器学习建模过程需要一定的正样本数用来分析用户行为模式,即当预测窗口期内满足目标条件的用户过少时,将会导致建模失败,如果您遇到该问题,为保证建模成功,请补充用户数据或修改预测目标。 |
| 正样本人数不足1w,无法建模 | 在您保存标签配置时,可能会弹出该提示语。通常是由于系统内预测目标的用户数不足导致的;预测目标的人数取决于您设置的「预测窗口期」和「标签规则条件」,在预测窗口期内如果系统内符合您标签规则的人数过少(即少于1w),则会弹出该提示。请您谅解,为满足模型训练条件和保障训练结果精度,正样本人数至少需要1w。 |